
- 首页
- 上一级
- ArrayList、LinkedList与Vector的区别?.md
- ArrayList的subList方法有什么需要注意的地方吗?.md
- ArrayList的序列化是怎么实现的?.md
- ConcurrentHashMap为什么在JDK1.8中使用synchronized而不是ReentrantLock.md
- ConcurrentHashMap为什么在JDK1.8中废弃分段锁?.md
- ConcurrentHashMap在哪些地方做了并发控制.md
- ConcurrentHashMap是如何保证fail-safe的?.md
- ConcurrentHashMap是如何保证线程安全的?.md
- HashMap、Hashtable和ConcurrentHashMap的区别?.md
- HashMap在get和put时经过哪些步骤?.md
- HashMap是如何扩容的?.md
- HashMap用在并发场景中有什么问题?.md
- HashMap的hash方法是如何实现的?.md
- HashMap的remove方法是如何实现的?.md
- HashMap的容量设置多少合适?.md
- HashMap的数据结构是怎样的?.md
- JDK1.8中HashMap有哪些改变?.md
- Java8中的Stream用过吗?都能干什么?.md
- Java中的集合类有哪些?如何分类的?.md
- Set是如何保证元素不重复的.md
- Stream的并行流是如何实现的?.md
- hash冲突通常怎么解决?.md
- 为什么ConcurrentHashMap不允许null值?.md
- 为什么HashMap的Cap是2^n,如何保证?.md
- 为什么HashMap的默认负载因子设置成0.75.md
- 为什么在JDK8中HashMap要转成红黑树.md
- 什么是COW,如何保证的线程安全?.md
- 什么是fail-fast?什么是fail-safe?.md
- 你能说出几种集合的排序方式?.md
- 同步容器(如Vector)的所有操作一定是线程安全的吗?.md
- 如何将集合变成线程安全的?.md
- 遍历的同时修改一个List有几种方式?.md
✅为什么HashMap的Cap是2^n,如何保证?
典型回答
本文的源码是基于Java 7的,主要是1.7中有个单独的IndexFor方法,讲起来更方便大家理解,而Java8中虽然没有这样一个单独的方法,但是查询下标的算法也是和Java 7一样的。
JDK1.7的HashMap的hash方法的实现中,是通过两个方法int hash(Object k)和int indexFor(int h, int length)来实现。
我们重点来看一下indexFor方法。为了方便大家理解,我们看Java 7的中该实现细节:
static int indexFor(int h, int length) {
return h & (length-1);
}
indexFor方法其实主要是将hashcode换成链表数组中的下标。其中的两个参数h表示元素的hashcode值,length表示HashMap的容量。那么return h & (length-1)是什么意思呢?
其实,他就是取模。Java之所有使用位运算(&)来代替取模运算(%),最主要的考虑就是效率。
为什么是用&而不是用%呢?因为&是基于内存的二进制直接运算,比转成十进制的取模快的多。又因为X % 2^n = X & (2^n – 1),可以把%运算转换为&运算。所以,hashMap的capacity一定要是2^n。这样,HashMap计算hash的速度才够快
为什么**X % 2^n = X & (2^n – 1)**?
假设n为3,则2^3 = 8,表示成2进制就是1000。2^3 -1 = 7 ,即0111。
此时X & (2^3 – 1) 就相当于取X的2进制的最后三位数。
从2进制角度来看,X / 8相当于 X >> 3,即把X右移3位,此时得到了X / 8的商,而被移掉的部分(后三位),则是X % 8,也就是余数。
上面的解释不知道你有没有看懂,没看懂的话其实也没关系,你只需要记住这个技巧就可以了。或者你可以找几个例子试一下。
如: 6 % 8 = 6 ,6 & 7 = 6 10 % 8 = 2 ,10 & 7 = 2
所以,return h & (length-1);只要保证length的长度是2^n 的话,就可以实现取模运算了。
所以,因为位运算直接对内存数据进行操作,不需要转成十进制,所以位运算要比取模运算的效率更高,所以HashMap在计算元素要存放在数组中的index的时候,使用位运算代替了取模运算。之所以可以做等价代替,前提是要求HashMap的容量一定要是2^n 。
如何保证的?
要想保证HashMap的容量始终是2^n次方,需要在Map初始化的时候,和扩容的时候分别保证
初始化时期保证
当我们通过HashMap(int initialCapacity)设置初始容量的时候,HashMap并不一定会直接采用我们传入的数值,而是经过计算,得到一个新值,目的是提高hash的效率。(1->1、3->4、7->8、9->16)
在JDK 1.7和JDK 1.8中,HashMap初始化这个容量的时机不同。JDK 1.8中,在调用HashMap的构造函数定义HashMap的时候,就会进行容量的设定。而在JDK 1.7中,要等到第一次put操作时才进行这一操作。
看一下JDK是如何找到比传入的指定值大的第一个2的幂的:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
上面的算法目的挺简单,就是:根据用户传入的容量值(代码中的cap),通过计算,得到第一个比他大的2的幂并返回。
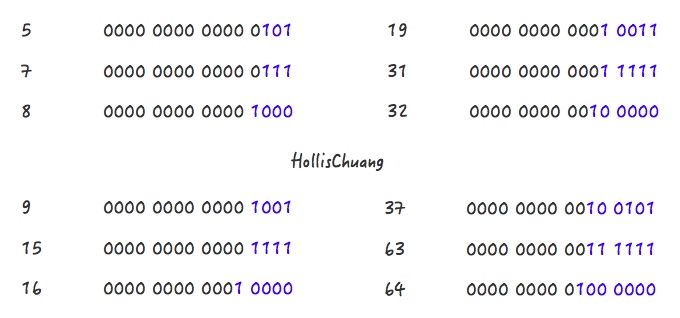
请关注上面的几个例子中,蓝色字体部分的变化情况,或许你会发现些规律。5->8、9->16、19->32、37->64都是主要经过了两个阶段。
Step 1,5->7
Step 2,7->8
Step 1,9->15
Step 2,15->16
Step 1,19->31
Step 2,31->32
对应到以上代码中,Step1:
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
对应到以上代码中,Step2:
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
Step 2 比较简单,就是做一下极限值的判断,然后把Step 1得到的数值+1。
Step 1 怎么理解呢?其实是对一个二进制数依次无符号右移,然后与原值取或。其目的对于一个数字的二进制,从第一个不为0的位开始,把后面的所有位都设置成1。
因为cap是int类型的,所以最多需要右移16位即可获取其最大值。
随便拿一个二进制数,套一遍上面的公式就发现其目的了:
1100 1100 1100 >>>1 = 0110 0110 0110
1100 1100 1100 | 0110 0110 0110 = 1110 1110 1110
1110 1110 1110 >>>2 = 0011 1011 1011
1110 1110 1110 | 0011 1011 1011 = 1111 1111 1111
1111 1111 1111 >>>4 = 1111 1111 1111
1111 1111 1111 | 1111 1111 1111 = 1111 1111 1111
通过几次无符号右移和按位或运算,我们把1100 1100 1100转换成了1111 1111 1111 ,再把1111 1111 1111加1,就得到了1 0000 0000 0000,这就是大于1100 1100 1100的第一个2的幂。
好了,我们现在解释清楚了Step 1和Step 2的代码。就是可以把一个数转化成第一个比他自身大的2的幂。
但是还有一种特殊情况套用以上公式不行,这些数字就是2的幂自身。如果cap=4套用公式的话。得到的会是 8,不过其实这个问题也被解决了,重点就在**int n = cap - 1;**这行代码中,HashMap会事先将用户给定的容量-1,这样就不会出现上述问题了
总之,HashMap根据用户传入的初始化容量,利用无符号右移和按位或运算等方式计算出第一个大于该数的2的幂。
扩容时期保证
除了初始化的时候回指定HashMap的容量,在进行扩容的时候,其容量也可能会改变。
HashMap有扩容机制,就是当达到扩容条件时会进行扩容。HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。
在HashMap中,threshold = loadFactor * capacity。
loadFactor是装载因子,表示HashMap满的程度,默认值为0.75f,设置成0.75有一个好处,那就是0.75正好是3/4,而capacity又是2的幂。所以,两个数的乘积都是整数。
对于一个默认的HashMap来说,默认情况下,当其size大于12(16*0.75)时就会触发扩容。
下面是HashMap中的扩容方法(resize)中的一段:
if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
因为oldThr已经是2^n了,所以oldThr无符号左移之后,是oldThr * 2,自然也是2^n。至于后续HashMap是如何扩容的,请听下回分解~
知识扩展
负载因子和容量有什么关系?
HashMap中有几个属性,如capacity记录了HashMap中table的length,size记录了HashMap中KV的对数,threshold记录了扩容的阈值(=loadFactor*capacity),loadFactor则是负载因子,一般是3/4
当HashMap刚刚初始化的时候,如果不指定容量,那么threshold默认是16,如果指定,则默认是第一个比指定的容量大的2的幂(如上文所说),此时size=0,capacity=threshold=16,loadfactor默认是0.75F
当HashMap开始装载的时候(即调用#put方法),那么size=KV的对数,capacity=16暂时不变,threashold=12(loadfactor*capacity),loadfactor=0.75F
当HashMap中的size > 12(threashold)时,capacity=32(16 << 1),threashold=24(loadfactor*capacity),loadfactor=0.75F
由此可得,负载因子决定了什么时候扩容,也间接的决定了HashMap中容量的多少